Datasource Playground
The Datasource Playground provides a testing environment where you can preview how your datasource responds to queries before integrating it with your AI peers. This helps you validate your data structure, test search relevance, and optimize your datasource configuration.
Overview
The Playground allows you to:
- Test Queries: See what content your datasource returns for specific questions
- Preview Scores: View relevance scores for matching content
- Validate Data: Ensure your datasource contains the right information
- Optimize Search: Tune search parameters and limits
- Debug Issues: Identify why certain queries don't return expected results
Accessing the Playground
- Navigate to Settings → Datasources
- Select a datasource
- Click the Playground tab
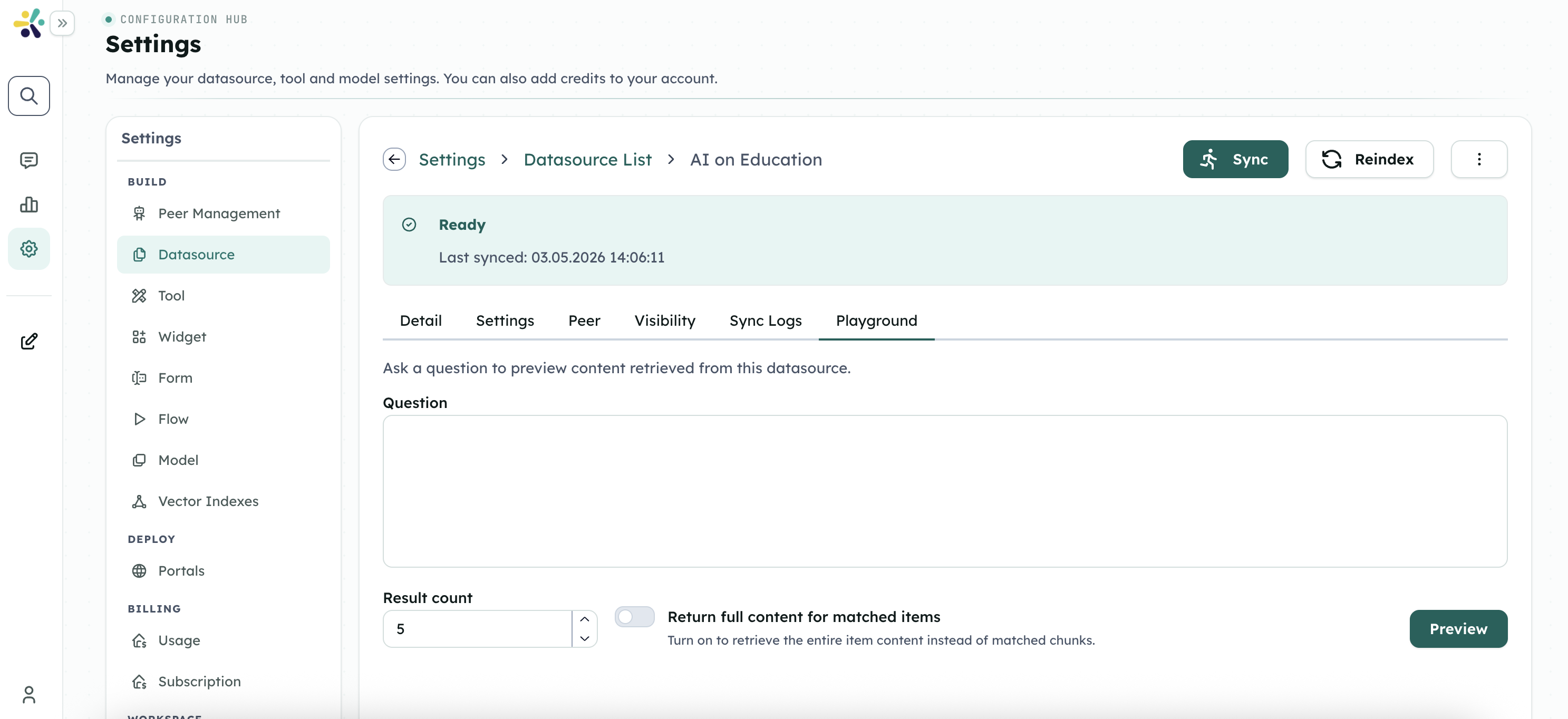
Using the Playground
Basic Query Testing
Enter a Question
- Type a natural language question in the text area
- Use the same type of questions your users will ask
- Be as specific as possible for accurate results
Configure Options
- Result Count: Choose how many results to return (1-20)
- Include Full Content: Toggle to see entire documents vs. matching chunks
Run the Query
- Click Preview to execute the search
- View results with relevance scores
- Examine the content returned
Understanding Results
Each result includes:
- Dataset Name: Which dataset the content came from
- Relevance Score: Cosine similarity score (0-1, higher is better)
- Item ID: Unique identifier for the content item
- Content: The actual text that would be provided to the AI
Result Scores
- 0.8 - 1.0: Highly relevant, excellent match
- 0.6 - 0.8: Good match, relevant content
- 0.4 - 0.6: Moderate relevance, may need better data
- Below 0.4: Low relevance, likely not useful
Configuration Options
Result Count
- Default: Based on your datasource
searchLimitsetting (max 20) - Recommendation: Start with 5-10 results
- Higher counts: Better for comprehensive coverage
- Lower counts: Faster processing, more focused results
Include Full Content
When enabled:
- Returns the complete content of matched items
- Useful for document-style datasources
- Provides full context
When disabled (default):
- Returns only relevant chunks that matched the query
- Better for large documents split into sections
- More focused, specific content
Best Practices
1. Test Diverse Questions
Test different types of queries:
✅ Specific questions: "What is the refund policy?"
✅ Broad topics: "customer support procedures"
✅ Edge cases: "troubleshooting login issues"
✅ Common variations: "how do I return an item" vs "returns process"2. Evaluate Score Thresholds
Monitor the scores to establish quality thresholds:
- If good answers score below 0.6, consider improving your data
- If irrelevant content scores above 0.7, refine your content structure
- Aim for relevant results to consistently score above 0.7
3. Optimize Data Based on Results
If results are poor:
Low Scores for Relevant Content:
- Content might be too fragmented
- Add more context to your documents
- Include relevant keywords in your content
Wrong Content Returned:
- Improve document metadata
- Break content into more logical sections
- Remove duplicate or redundant information
No Results Found:
- Check if content actually exists in the datasource
- Verify the datasource has been synced
- Ensure embedding model is configured
4. Test After Changes
Re-test queries after:
- Syncing new data
- Changing chunk size
- Updating embedding model
- Modifying vector index configuration
Common Use Cases
1. Pre-Deployment Validation
Before deploying a datasource to production:
Test Checklist:
□ Core product questions return accurate information
□ Troubleshooting queries find relevant help articles
□ Company policy questions retrieve correct policies
□ All major use cases return results with scores > 0.7
□ No irrelevant content appears in top 5 results2. Content Quality Assessment
Validate your documentation quality:
- Test with real user questions from support tickets
- Check if answers are found in the datasource
- Identify gaps in documentation
- Prioritize content creation based on missing answers
3. Search Tuning
Optimize search parameters:
- Test with different result limits
- Compare chunked vs. full content results
- Evaluate if additional context improves responses
- Determine optimal
searchLimitfor your use case
4. Troubleshooting
Debug datasource issues:
Symptom: AI peer gives incorrect answers
- Test the same question in Playground
- Check if correct content is returned
- Verify relevance scores
- Determine if issue is with datasource or peer configuration
Symptom: AI peer says "I don't know"
- Run the user's question in Playground
- Check if any results are returned
- Review scores to see if content is relevant enough
- Add missing content or improve existing content
Limitations
- Maximum Result Limit: 20 results per query
- Query Timeout: Long queries may timeout after 30 seconds
- No Caching: Each playground query performs a fresh search
- Vector Search Only: Tests vector similarity, not full text search
Tips for Better Results
Content Formatting
Structure your content for optimal retrieval:
Good ✅
# Refund Policy
Our refund policy allows customers to return items within 30 days.
To request a refund:
1. Contact support
2. Provide order number
3. Describe the issueLess Optimal ⚠️
Refund: 30 days, contact support, order number neededTest Question Variety
Include different question formats:
- Direct questions: "What is X?"
- How-to questions: "How do I do Y?"
- Problem-solving: "Why isn't Z working?"
- Comparison questions: "What's the difference between A and B?"
Iterative Improvement
- Run initial tests
- Identify poorly performing queries
- Improve content or structure
- Re-sync datasource
- Test again
- Repeat until satisfied
Related Documentation
- Datasource Management - Creating and managing datasources
- Vector Providers - Understanding vector storage
- Peer Settings - Configuring datasource usage in peers
- Developer Hub - API and SDK documentation
Troubleshooting
No Results Returned
Possible Causes:
- Datasource hasn't been synced yet
- Question doesn't match any content
- Vector index not properly configured
- Embedding model mismatch
Solutions:
- Sync the datasource
- Try broader or different questions
- Check datasource status
- Verify vector index connection
All Scores Are Low
Possible Causes:
- Content is too fragmented
- Poor content quality
- Embedding model not suitable for your content type
Solutions:
- Increase chunk size in datasource settings
- Improve content structure and clarity
- Try a different embedding model
- Add more context to your documents
Irrelevant Results
Possible Causes:
- Similar keywords in unrelated content
- Poor content organization
- Need better content boundaries
Solutions:
- Organize content into focused datasets
- Remove duplicate or redundant information
- Use more specific language in your content
- Consider using metadata filtering
Summary
The Datasource Playground is an essential tool for:
- Validating datasource content before production use
- Troubleshooting search quality issues
- Optimizing search parameters
- Understanding what AI peers will retrieve
Recommended Workflow:
- Create and sync datasource
- Test with representative questions
- Evaluate results and scores
- Improve content as needed
- Deploy to peers
- Monitor and iterate based on real usage
Regular testing in the Playground ensures your AI peers have access to the right information and can provide accurate, helpful responses to users.